Jill-Jênn Vie
Researcher at Inria
% Fairness et confidentialité en IA pour l’éducation :\newline risques et opportunités % Jill-Jênn Vie % 26 janvier 2023 — institute: \includegraphics[height=1cm]{figures/inria.png} \includegraphics[height=1cm]{figures/soda.png} colorlinks: true lang: fr aspectratio: 169 biblio-style: authoryear biblatexoptions: natbib header-includes: - \usepackage{bm} - \usepackage{tikz} - \usepackage{booktabs} - \usepackage{colortbl} - \DeclareMathOperator\logit{logit} - \def\Dt{D_\theta} - \def\E{\mathbb{E}} - \def\logDt{\log \Dt(x)} - \def\logNotDt{\log(1 - \Dt(x))} - \newcommand\mycite[3]{\textcolor{blue}{#1} “#2”.~#3.} - \usepackage{etoolbox} - \AtEndPreamble{\DefineBibliographyExtras{french}{\restorecommand\mkbibnamefamily}} —
#
:::::: {.columns} ::: {.column width=33%} Découvert l’algorithmique par les compétitions de programmation (Prologin)\medskip
\small
Entraîneur de l’X au ICPC
 :::
::: {.column width=34%}
Fondé Girls Can Code! en 2014 (toujours via Prologin)\medskip
:::
::: {.column width=34%}
Fondé Girls Can Code! en 2014 (toujours via Prologin)\medskip
\small
Stages de prog° pour filles
 :::
::: {.column width=33%}
Milité en faveur d’une agrégation d’informatique\medskip
:::
::: {.column width=33%}
Milité en faveur d’une agrégation d’informatique\medskip
\small
1\textsuperscript{re} édition en 2022
\centering \vspace{5mm}
 {width=50%}
{width=50%}
\vspace{5mm}
 :::
::::::
:::
::::::
Sujets de recherche dans l’équipe Soda
Machine learning sur des données d’humains
- Données manquantes, inférence causale
- Représentations de bases de données
- trajectoires de patients dans un hôpital (ex. AP-HP)
- trajectoires d’apprenants sur une plateforme
- Applications en santé et éducation
Nos ingénieurs de recherche sont les développeurs principaux de la bibliothèque scikit-learn
#

Mesurer les connaissances des apprenants à un instant donné
Théorie de la réponse à l’item (Rasch, 1961) (Lord, 1986) et un peu (Binet, 1905)
Tests adaptatifs $\to$ premières évaluations personnalisées par ordinateur (1970-1980)
Compromis entre bien mesurer et poser peu de questions
{height=7cm}
Tracer les connaissances au cours du temps : prédire la performance
Apprentissage d’une langue (jeux de données de Duolingo)
\includegraphics{figures/duolingo0.png}
Exercices de maths
\includegraphics[width=\linewidth]{figures/dkt.png}
Recommandations de la Commission européenne (guidelines)
IA & données pour l’éducation et la formation
- Facteur humain et supervision
- Transparence
- \alert{Diversité, non discrimination et \emph{fairness} (impartialité)}
- Bien-être sociétal et environnemental
- \alert{Confidentialité et gouvernance des données}
- Robustesse technique et sécurité
- Responsabilité
Diversité, non discrimination et fairness (impartialité)
- Le système est-il \alert{accessible} pour tous sans barrière ?
- Modes d’interaction appropriés pour les personnes à besoins spéciaux / interfaces appropriées
- Y a-t-il des procédures pour s’assurer que l’IA n’induira pas un traitement discriminatoire ou injuste pour ses utilisateurs ?
- La documentation du système ou son procédé d’entraînement indique-t-elle des biais potentiels dans les données ?
Fairness
“Different models with the same reported accuracy can have a very different distribution of error across population” (Hardt, 2017)
\pause
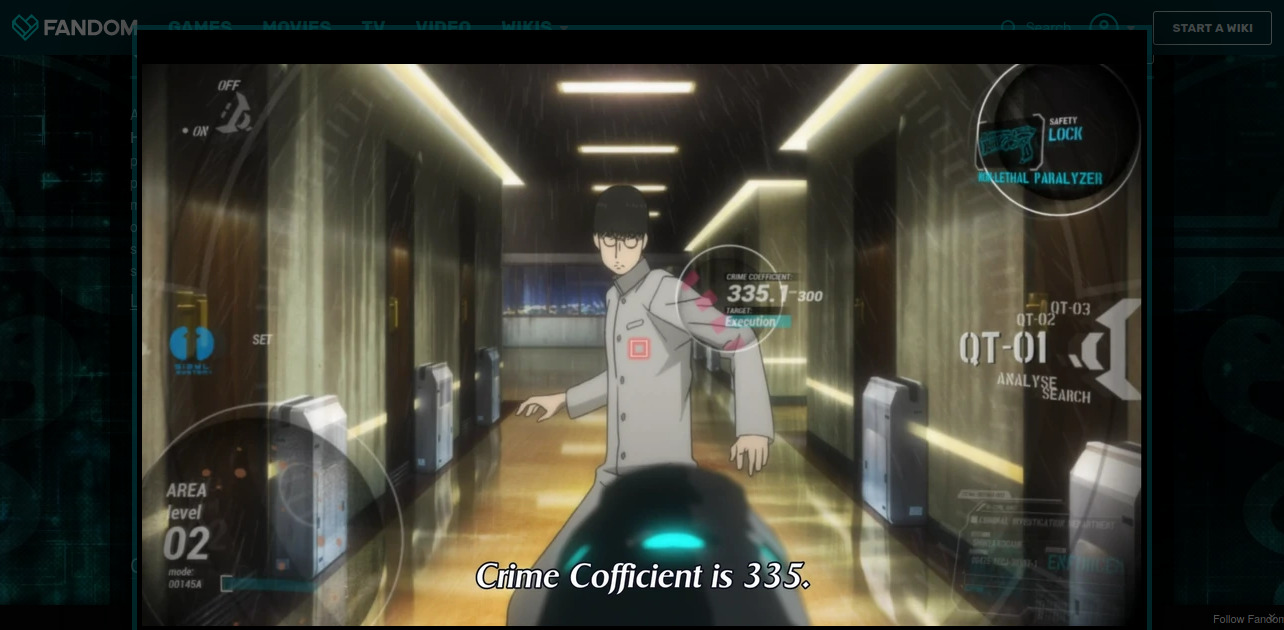
Scores de criminalité (regardez la série Psycho-Pass):
\centering
 {width=90%}
{width=90%}
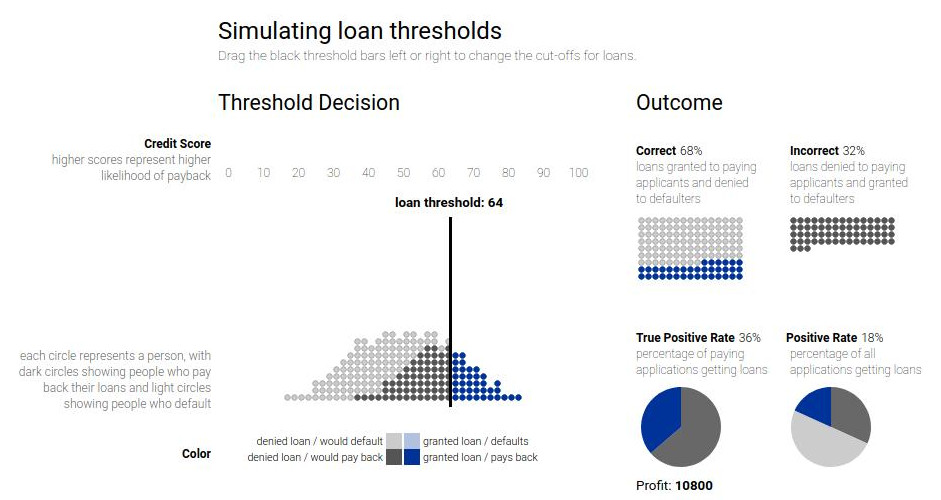
Beaucoup de définitions de fairness, parfois contradictoires
\centering
 {width=80%}
{width=80%}\raggedright
\fullcite{hardt2016equality}
Leur visualisation interactive : Attacking discrimination with smarter machine learning
Apprendre des représentations “justes”
:::::: {.columns}
::: {.column}
\centering
:::
::: {.column}
 :::
::::::
:::
::::::
\fullcite{zemel2013learning}
Voir aussi
\fullcite{hutchinson201950}
Classifieurs différents selon la catégorie de population
\centering
 {width=60%}
{width=60%}
\raggedright
Voir aussi \fullcite{gardner2019evaluating}
Importance de ne pas regarder/optimiser une seule métrique
Confidentialité et gouvernance des données
- Des mécanismes sont-ils en place pour s’assurer que les données sensibles sont anonymisées et protégées pour en limiter l’accès aux personnes nécessaires ?
- Les données sont-elles traitées dans le seul but pour lequel elles ont été collectées ?
- Les enseignants ont-ils un moyen de signaler des problèmes quant à la confidentialité ou la protection des données ? En sont-ils informés ?
- Simplement : est-ce que le système respecte la RGPD ? Les paramètres de confidentialité sont-ils modifiables ?
Intérêt pour les données synthétiques
- Il est difficile d’accéder à des données sensibles (procédures très longues pour la recherche)
- Un jeu de données qui est ouvert peut être archivé pour toujours
- Pourquoi ne pas avoir plutôt accès à :
- des statistiques (cf. DEPP)
- des modèles pré-entraînés
- des jeux de données synthétiques ? (ne serait-ce que pour la reproductibilité)
Les faits
La pseudonymisation, ce n’est pas suffisant
@narayanan2008robust ont réussi à dé-anonymiser le jeu de données pseudonymisé du prix Netflix de films vus et notés, avec les données publiques d’IMDb
Les données de grande dimension sont rarement $k$-anonymisables
- 4 points espace-temps sont suffisant pour caractériser de façon unique 95\% des trajectoires d’individus dans un jeu de données de 1,5 millions de lignes \citep{de2013unique}
- 15 données démographiques sont suffisantes pour réidentifier 99,96\% des Américains \citep{rocher2019estimating}
Les grands modèles de langage se souviennent des données d’entraînement
\fullcite{carlini2021extracting}
Modèles génératifs préservant la confidentialité
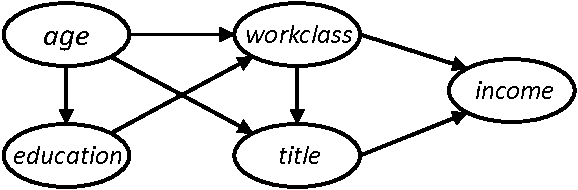
Confidentialité différentielle (differential privacy)
La sortie de l’algorithme doit être quasi indistinguable de selon si une personne manque dans le jeu de données d’entraînement.
Réseaux bayésiens PrivBayes \citep{zhang2017privbayes}
 {width=50%}
{width=50%}
Générer des données individuelles à partir de données agrégées
\fullcite{acharya2022gensyn}
Intuition
Échantillonner les données sensibles selon la distribution
\centering
 {width=50%}
{width=50%}
Schéma
- Utilité
- On doit pouvoir déduire des analyses similaires à partir du jeu de données réel et à partir du jeu de données synthétique
- Réidentification
- Il faut empêcher que la réidentification soit facile / le jeu de données synthétique ne doit pas compromettre la confidentialité des participants
\centering \begin{tikzpicture}[ xscale=3.5, yscale=2, data/.style={draw}, >=stealth ] \node[data,text width=1.5cm,text centered] (original) at (0,0) {Données\ réelles}; \node[data,text width=2.5cm,text centered] (training) at (1,0) {Données\ d’entraînement}; \node[data,text width=2.5cm,text centered] (fake) at (1,-1) {Données\ synthétiques}; \node[data] (real-irt) at (2,0) {Résultats}; \node[data] (fake-irt) at (2,-1) {Résultats}; \draw[->] (original) edge node[above=5mm] {échantillonner} (training); \draw[->] (training) edge node[right] {générer} (fake); \draw[<->] (real-irt) edge node[right] {similaires} (fake-irt); \draw[->,dashed,bend right] (original) edge (training); \draw[->,dashed,bend left=60,text width=2cm,text centered] (fake) edge node[below left] {réidentifier} (training); \draw[->] (training) edge node[above] {analyse} (real-irt); \draw[->] (fake) edge node[above] {analyse} (fake-irt); \end{tikzpicture}
\raggedright \small
\fullcite{Vie2022}
Résultats quantitatifs
{width=49%}
{width=49%}
$\leftarrow$ réidentification (aussi bas que possible)
$\downarrow$ différence entre résultats (aussi bas que possible)
#
Génération fidèle
\centering
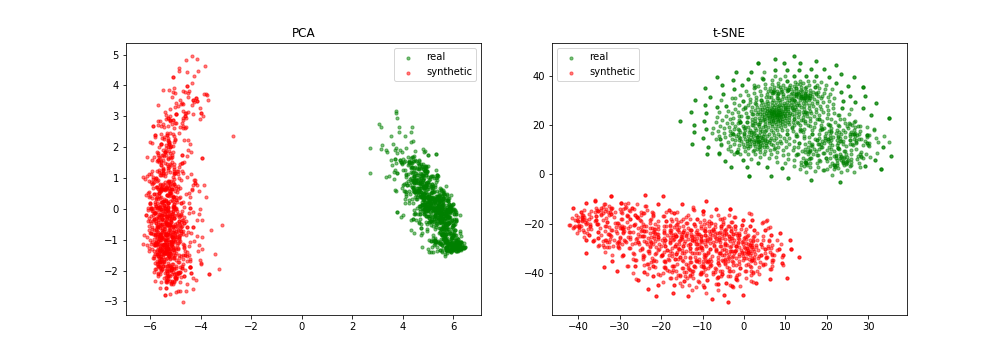 {width=80%}
{width=80%}
Génération non fidèle
\centering
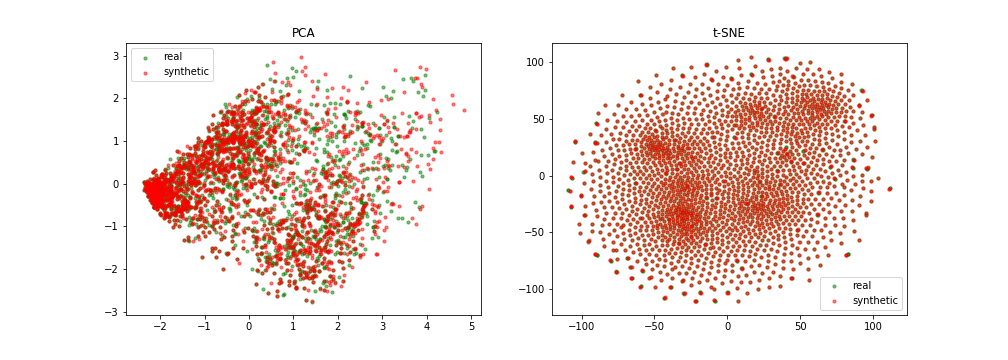 {width=80%}
{width=80%}
Conclusion
- Ouvrons massivement les données de gens qui n’existent pas
- Il faut mesurer les discriminations pour réduire les inégalités
- (donc regarder plus d’une métrique)
\vspace{1cm}
Merci ! Questions ? \hfill Ces slides sur \href{https://jjv.ie/slides/relia.pdf}{jjv.ie/slides/relia.pdf}